关于《工业大数据创新竞赛白皮书》 你想知道的都在这里了
供稿:北京天泽智云科技有限公司
- 关键词:天泽智云,工业大数据,工业智能
- 作者:金超
- 摘要:2月1日在2018工业互联网峰会上,《工业大数据创新竞赛白皮书(2017)》(简称白皮书)正式发布。白皮书是在工信部信息化和软件服务业司、工业互联网产业联盟指导下,工业大数据创新竞赛组委会在北京天泽智云科技有限公司的倾力支持下,组织参赛者编写的。
2月1日在2018工业互联网峰会上,《工业大数据创新竞赛白皮书(2017)》(简称白皮书)正式发布。白皮书是在工信部信息化和软件服务业司、工业互联网产业联盟指导下,工业大数据创新竞赛组委会在北京天泽智云科技有限公司的倾力支持下,组织参赛者编写的。
白皮书收录了2017年工业大数据竞赛-风机叶片结冰故障预测的获奖算法,组成解法集,在工业大数据分析的方法论上具有重要的指导意义,在风力发电机行业尤其具有示范作用。下面天泽智云为大家带来白皮书的首波剧透和独家解读!
关于工业大数据创新竞赛
2017年7月-12月,在工信部指导下,中国信息通信研究院联合业界同仁举办首届工业大数据创新竞赛,这是首次由政府主管部门组织的工业大数据领域权威的全国性创新竞赛。天泽智云核心技术团队,对大数据竞赛提供了从选题、验证、评审和总结编写解法集的全程支持。

工业大数据与PHM(故障预测与健康管理)
工业大数据分析是一个非常广而杂的领域,不仅包含PHM领域,同时也包括统筹、化工等不同学科,以及很多建模方式等多方面的内容。但是为什么近几年PHM得到了广泛的关注?
随着2014年工业4.0概念的提出,我们逐渐发现目前企业最关心的问题或者最大的痛点在于设备的健康状况,以及机器如何能实现自知的状态。什么是自知?传统企业的维护模式一般是周期性或者基于现象的反馈对机器进行维护,但当我们能够体察到机器的一些现象时,可能已经失效。因此我们要做的就是运用工业大数据将这些不可见的现象量化和显性化,进而挖掘机器里的衰退现象。而这正是PHM最核心的功能。
PHM的前世今生
其实PHM成为一门学科还不到十年的时间,非常年轻。在美国与PHM直接相关的有PHM Society和IEEE两个协会,从2008年起基本每年都会举办相关的竞赛,下图为部分竞赛题目。

在PHM竞赛中,工业大数据切入的角度是如何利用存量的历史数据来挖掘其中的价值,从而实现健康评估、故障预测和故障诊断等具体的业务目标。这些题目之所以有意义,是因为它切实映射到了我们工业大数据分析的几个挑战:
第一,数据状况是否满足建模需求?
与客户接触过程中,客户经常咨询我们如何使用数据,或者要达到某个目标需要哪些数据。其实这也反映出几个大家非常关心的问题,就是工业大数据或工业智能技术如何与企业现状相结合?现有的数据状况满足什么样的标准?有没有具体衡量的维度、或者方法论来评价数据状态是否满足建模需求?
第二,方法如何选择?
不论传统的机理模型,还是经典的统计分析,甚至是我们经常提到的人工智能、机器学习的算法,其实都越来越模块化、开元化、社区化。当这个领域越来越开放的时候,我们如何把这些技术正确的对应到场景上,其实是大家非常关心的一个问题,就是说这些方法应该如何选择。

中国工业大数据竞赛与美国PHM竞赛殊途同归
美国的PHM竞赛涉及到很多工业场景,包括航空发动机、齿轮箱、风机测风仪、半导体、轨道交通等,没有一个特定的领域;此次工业大数据竞赛聚焦的是风电领域,未来也将涉及更多其他工业领域。所以竞赛的目的:
第一是对数据与应用问题的积累。找到通用的应用场景,或者让大家尽量见到更多的工业场景,进而积累工业应用问题。
第二是场景多样性。大家可以从不同的工业场景中比较不同方法的异同,从而总结出一些通用的方法。
第三是解法思路的可参考性。工业大数据分析需要从共性和差异性两个层面同时总结和切入。
中国首届工业大数据创新竞赛意义深远
我国举办工业大数据创新竞赛的意义非常显著。相比美国的PHM竞赛的关注度,参赛人数最多也不到100人,能达到50人就已经非常欣慰了;而此次中国举办的第一次工业大数据竞赛就有超过1500人参赛,分别有830支和630支队伍参加两个竞赛题目,其中60%以上来自于高校学生,涉及数据挖掘、控制工程、工业机器人、测控技术、计算机等多个领域,影响力非常大。
“我们为这个大赛感到骄傲,无论从影响力、专业性还是竞赛的激烈程度,以及论文或者解法的质量来说,我觉得在某种程度上不亚于美国。”
— 金超博士
竞赛推动创新探索、实践指导与人才发展
创新探索- 这次比赛的数据都是来源于真实的工业场景。由一家知名风机制造商提供的数据,数据来源非常宝贵,作为一个非常好的研究基础,可以切实地解决很多工业中大家面对的一线问题,然后进行创新并做一些理论研究。
实践指导- 拿到了一线的数据,本身的应用也更贴近实际问题,更有益于产学研用紧密结合的紧密结合,加速技术转化落地。李杰教授认为,数据应该来自于工业,所以在他领导下的IMS中心很少见到试验台,我们都是去到工业企业现场解决最头疼的问题。
人才发展- 从这次竞争的激烈程度来看,能发掘出很多优秀的工业大数据建模人才,可以将这些人才与更多的发展平台进行对接,为中国的工业振兴发挥更大的价值。
关于《工业大数据创新竞赛白皮书(2017)》

白皮书目录
天泽智云技术研发副总裁金超博士指出,典型的PHM系统从设备中提取原始数据,得到的特征经过模块化的分析实现不同应用,提供可执行信息,让用户直观地看到设备的洞察。同时可执行的信息也可以被输入到现有的生产系统里面做对接,然后直接传导到指令。在这个过程中,用户可以对模型进行维护,对参数进行调整。

典型的PHM系统
工业大数据创新竞赛其实并不是要构建整个的这样一个系统,而是关心模块化分析引擎,或者说是从如何把原始数据转化成相应的业务目标做支撑的一个环节。在做工业大数据建模分析的时候,可以分为以下几步:

工业大数据的建模过程
第一步,业务场景分析:工业大数据分析不同于互联网,对通过数据挖掘来泛泛寻找相关性这种模式在成本上无法承受。工业大数据分析应该从业务入手,在了解行业背景、分析用户痛点之后,制定明确的数据服务目标,定义工业数据分析系统的功能与边界。
第二步,数据问题定义:在确定业务目标之后,需要对问题进行数学化的定义。在工业中,并非所有的问题都适用于数据驱动的建模方式。根据数据的数量、质量、与可采集变量的完整性,明确数据建模的策略与详细流程。
第三步,数据场景化:原始数据往往因为数据质量、工况完整性、标签缺失等问题无法用来直接建模。在建模之前,有必要检测数据质量,将数据与业务场景相对应,之后提取能够反映建模对象健康状态的特征,为后续模型输入做准备。
第四步,模型建立:这一步与通常意义上的机器学习过程类似。不同的是,在工业数据预测性分析中,建模是更加强调模型的可靠性、泛化能力、以及可解释性。
第五步,模型价值评估:模型本身性能与准确性不是工业数据分析的唯一衡量标准。如何能够让模型产生准确的可执行信息,快速支持用户决策,改善设备健康状态,优化运维效率,是建模中需要着重强调的关键评估角度。
第六步,模型部署与实施:模型本身不产生价值,嵌入软件产品中支持业务改善的模型才有价值。与离线的验证不同,工业系统的模型上线后,仍需要被维护、管理、以及不断迭代,以适应变换的工业场景与可能出现的问题,持续为用户提供设备洞察,提高生产力。
以上过程我们在白皮书中给出了结冰预测应用实例供大家参考理解。
白皮书收录的解法集
金超博士指出,本白皮书收录了竞赛中第一个题目(风机结冰故障分析)的5个获奖解法集,由纯粹基于机理、基于数据驱动,以及机理与数据融合三个流派组成,分别由以下5支参赛队提供详细解法与结果讨论。

在此列举融入机理及数据驱动两个代表解法。
1. 融入机理代表解法:基于物理原理+KNN分类的混合预测模型–济中节能
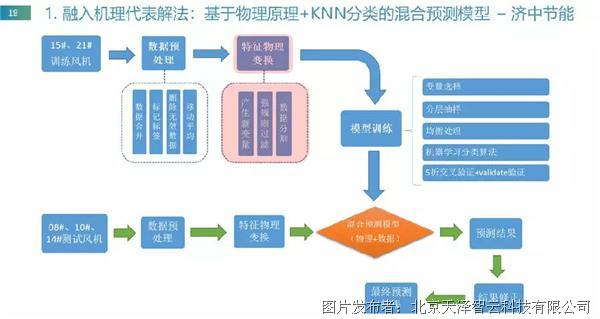
资料来源:济中节能工业大数据竞赛答辩终稿
济中节能机理融入的接口在特征这一层,该团队的模型融入了风机领域知识,主要目的是在数据量不足的情况下增强模型的泛化能力。通过增加机理变量、强规则过滤和数据分割的方法对数据进行处理,所以最终取得比较理想的效果。
2. 数据驱动代表:基于数据驱动和非均衡数据学习的故障预测研究 –北京邮电大学

资料来源:北京邮电大学工业大数据竞赛答辩终稿
学术组第一名北邮则是从数据的角度直接切入,在前期的数据观察上做了很多工作,同时也注意到了数据严重不平衡的现象,并给出了相应的应对方法。模型从机器学习的角度出发,采用集成模型平均的建模策略,建立结冰预测模型。
总 结
数据的预处理地位在上升,数据的预处理对最后的预测结果影响不亚于模型本身。
融入领域知识之后往往可以增强模型的泛化能力与准确性,其结果通常会优于没有领域知识的纯粹机器学习模型,尤其在数据质量不好的情况下。
在增加机器学习模型复杂度后,其准确性有可能与“机理+简单模型”的结果相当。但是,其代价是模型训练时间随着其准确度的上升而显著增加,并且复杂性增加后其结果可解读性变差。
《工业大数据创新竞赛白皮书(2017)》希望传递的理念是,对于不同的工业应用问题,要根据数据的质量、完整性、以及该问题对模型性能与准确度的要求,来灵活选择不同的建模策略,紧扣业务目标,用工程化的思维不断降低模型中的不确定性。
致 谢
在此向指导单位、编写单位、指导专家和编写组成员致以诚挚的感谢!
